opsetのversionごとのOperation
以下のheaderに各Versionごとに定義されてるOperationが記述されてる。
WSLでapt updateするときの対処
sudo bash -c 'echo "nameserver 8.8.8.8" > /etc/resolv.conf' sudo bash -c 'echo "nameserver 8.8.4.4" >> /etc/resolv.conf'
DLフレームワークの量子化リンク集
PyTorch
Introduction to Quantization on PyTorch
Introduction to Quantization on PyTorch | PyTorch
Tensorflow
onnxruntime
Optimize your Teneosorflow Lite models
Tensorflow Lite Optimizationの発表まとめ
GoogleIOで発表のあったTensorflow Lite Optimizationに関する発表に関してざっくりまとめてみました。
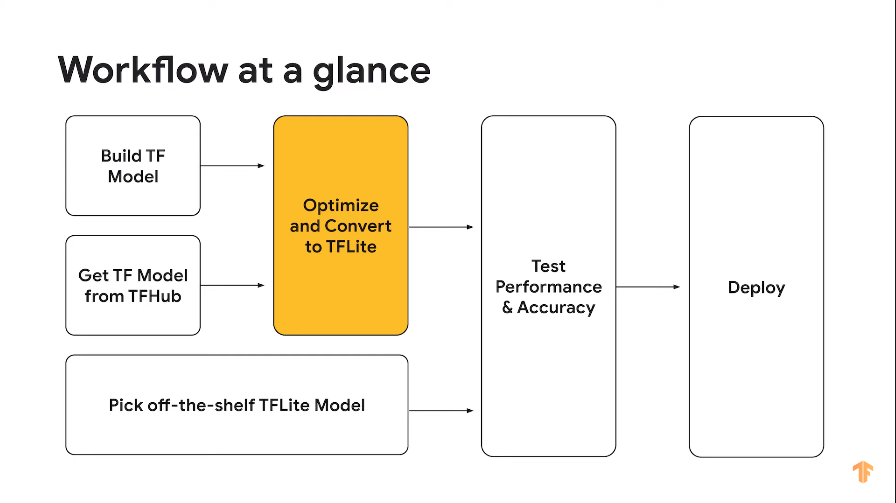
デプロイまでの流れ
Quantization
エッジデバイスでの推論向けにモデルを小さくしたり、レイテンシを削減するツールキットの1つに量子化があります。
量子化は精度が低めの近似表現に変換する作業を指します。 モデルによってはトレーニング済みのモデルを量子化するよりも、量子化したモデルをトレーニングした方が精度が良い場合があります。 なのでTensorflowはPost Training Quantization向けAPIとTraining Aware Quantization APIを提供します。
Post Training Quantization Example

Weight Pruning
トレーニング時のテクニック、不必要なLayer間の接続を削除することにより、より疎な重みを作り出す。推論時は0はスキップされるので、レイテンシを改善することができる。


いくつかのハードやモデルでWeight Pruningの効果を検証したところ、推論スピードがアップし、精度の低下はわずかでした。 また、pruningとquantizationは同時に利用することができます。つまりpruned_modelを量子化し、さらなる推論モデルの最適を進めることができます。
XNNPACKを利用したCPUでの推論高速化

Maximum available performance

GPU Delegation

DeepLearningフレームワークの推論時間の観察
pytorchで定義されたモデルをonnx, tflite形式へと変換し推論の実行時間を計測した。
pytorch->onnx->tensorflow->tfliteへの変換は以下の変換処理をまとめたライブラリを利用。 また、モデルのconvertする際には量子化等は適用しておらず、fp32のまま推論。
測定環境
| CPU | pytorch | onnx | onnxruntime | tensorflow |
|---|---|---|---|---|
| AMD Ryzen 5 3600 6-Core Processor | 1.8.1 | 1.9.0 | 1.7.0 | 2.5.0 |
推論時間の測定結果
実行時間は100回連続推論させた平均ですが、数値は参考程度にご覧ください。 ちなみにpytorchとtfliteの推論一発目は実行時間がresnetだと100ms程遅いので(アルゴリズム選定とかでしたっけ?)推論1回目の結果は除いてあります。onnxruntimeは1回目も推論速度は早かったです。
- Resnet34
input_shape: (1, 3, 224, 224)
| pytorch | onnxruntime | tflite |
|---|---|---|
| 29.18ms | 12.29ms | 39.37ms |
- transformer
src_shape = (10, 32, 512)
tgt_shape = (20, 32, 512)
| pytorch | onnxruntime |
|---|---|
| 273.50ms | 92.80ms |
※transformerモデルのtfliteへの変換はまだうまくいってません。issue
この結果だけみるとonnxruntime良さそうです(tfとtorchで最適なshapeが異なっていて平等ではない可能性あり)
量子化した時とデバイスを変更したときにどうなるかって感じです。
convertした後のモデルでも眺めてみようかなー
測定コード
import torch import numpy as np import nne import torchvision input_shape = (1, 3, 224, 224) model = torchvision.models.resnet34(pretrained=True) torch.save(model, "resnet.pt") bm = nne.Benchmark(name='torch') input_data = np.array(np.random.random_sample(input_shape), dtype=np.float32) output_data = nne.infer_torch(model, input_data, bm=bm) ## onnx onnx_file = "resnet.onnx" bm = nne.Benchmark(name='onnx') nne.cv2onnx(model, input_shape, onnx_file) onnx_model = nne.load_onnx(onnx_file) nne.infer_onnx(onnx_model, input_data, bm=bm) ## tflite tflite_file = "resnet.tflite" bm = nne.Benchmark(name='tflite') nne.cv2tflite(model, input_shape, tflite_file) tflite_model = nne.load_tflite(tflite_file) nne.infer_tflite(tflite_model, input_data, bm=bm)
【golang】mapのvalueでsort
key, valueを保持する構造体を作って、sort interfaceを満たすように Len(), Swap(), Less()メソッドを実装してあげる。 これはstackoverflowに載っていた。
// A data structure to hold key/value pairs
type Pair struct {
Key string
Value int
}
// A slice of pairs that implements sort.Interface to sort by values
type PairList []Pair
func (p PairList) Len() int { return len(p) }
func (p PairList) Swap(i, j int) { p[i], p[j] = p[j], p[i] }
func (p PairList) Less(i, j int) bool { return p[i].Value < p[j].Value }
で、PairListの各要素にPairを詰めてあげれば、sortできると。
func rankByWordCount(wordFrequencies map[string]int) PairList{
pl := make(PairList, len(wordFrequencies))
i := 0
for k, v := range wordFrequencies {
pl[i] = Pair{k, v}
i++
}
sort.Sort(sort.Reverse(pl))
return pl
}