Optimize your Teneosorflow Lite models
Tensorflow Lite Optimizationの発表まとめ
GoogleIOで発表のあったTensorflow Lite Optimizationに関する発表に関してざっくりまとめてみました。
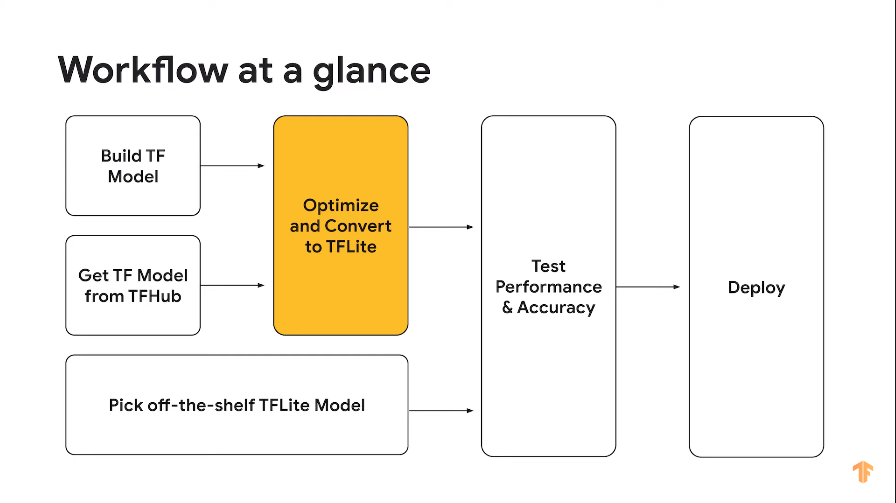
デプロイまでの流れ
Quantization
エッジデバイスでの推論向けにモデルを小さくしたり、レイテンシを削減するツールキットの1つに量子化があります。
量子化は精度が低めの近似表現に変換する作業を指します。 モデルによってはトレーニング済みのモデルを量子化するよりも、量子化したモデルをトレーニングした方が精度が良い場合があります。 なのでTensorflowはPost Training Quantization向けAPIとTraining Aware Quantization APIを提供します。
Post Training Quantization Example

Weight Pruning
トレーニング時のテクニック、不必要なLayer間の接続を削除することにより、より疎な重みを作り出す。推論時は0はスキップされるので、レイテンシを改善することができる。


いくつかのハードやモデルでWeight Pruningの効果を検証したところ、推論スピードがアップし、精度の低下はわずかでした。 また、pruningとquantizationは同時に利用することができます。つまりpruned_modelを量子化し、さらなる推論モデルの最適を進めることができます。
XNNPACKを利用したCPUでの推論高速化

Maximum available performance

GPU Delegation
